Gemini 2.5 Pro Preview (05-06) vs. Claude 3.7 Sonnet: A Benchmark Battle for AI Coding Supremacy
Introduction
The world of artificial intelligence has never moved faster. In 2025, large language models have leapt from laboratory curiosities to indispensable tools, powering everything from code generation to creative storytelling. In this high-stakes arena, two challengers stand out: Google’s freshly minted Gemini 2.5 Pro Preview (05-06) and Anthropic’s Claude 3.7 Sonnet. Both promise leaps in reasoning ability, multimodal understanding, and coding prowess—but which truly sets the new standard?
This article dives deep into the heart of the competition. We’ll chart their performance across human-judged leaderboards, dissect their technical underpinnings—context windows, multimodal inputs, knowledge cutoffs, pricing—and surface real-world accounts from developers grappling with each model’s quirks. By the end, you’ll have a clear map for when to pick Gemini’s raw power and when to lean on Claude’s thoughtful precision.
Background and Release Timelines
In the days leading up to its flagship developer conference, Google let rip a surprise: on May 6, 2025, Gemini 2.5 Pro Preview (05-06) went live. Branded the “I/O edition,” this build arrived early after whispers of exceptionally strong coding feedback, giving developers a head start on integrating its expanded capabilities. Accessible via the Gemini API, Google’s Vertex AI suite, AI Studio, and the familiar Gemini chatbot app on web and mobile, the preview preserves the same token-pricing tiers as its immediate predecessor—though with substantially beefed-up performance.
Anthropic, not to be outdone, quietly rolled out Claude 3.7 Sonnet in the opening months of 2025. Its headline feature, “Thinking Mode,” invites users to peer into the model’s step-by-step reasoning process—a page torn from the recent trend of transparent AI pipelines. Anthropic kept its established pricing intact: $3 per million input tokens and $15 per million output tokens, billing even the internal “thinking” tokens at those rates. Claude 3.7 Sonnet landed across Claude.ai, via Anthropic’s own API, and on major cloud platforms like Amazon Bedrock and Google Cloud’s Vertex AI, ensuring broad availability from day one.
Core Technical Specifications
Context Window
At the heart of any language model lies its capacity to hold context—and here, Gemini strides ahead with a staggering one-million-token window, expandable to two million for those truly epic inputs. In practical terms, that means entire codebases, lengthy legal briefs, or multi-chapter novels can be digested in a single prompt. Claude, by contrast, caps out at 200,000 tokens—ample for most conversational or document-summarization tasks, but a clear constraint when your project spans tens of thousands of lines of code.
Multimodal Capabilities
Beyond sheer text volume, multimodality has become table stakes. Gemini’s Preview doesn’t just read: it sees, hears, and watches. Text, images, audio clips, even video snippets all feed into its neural engine, enabling use cases from automated video summarization to voice-guided code review. Claude 3.7 Sonnet joins the image bandwagon but stops there—no audio transcription, no frame-by-frame video analysis. For any project that marries code with UX mockups or integrates spoken user feedback, Gemini holds the advantage.
Knowledge Cutoff & Model Architectures
Under the hood, both models share transformer-based lineages—but their knowledge cutoffs hint at whose training set went deeper into recent events. Gemini’s data pipeline extends through January 2025, capturing developments up to the new year. Claude’s last update halts at October 2024, meaning any breakthroughs or news after that point won’t register. When your query touches on the first months of 2025—say, a freshly published library or API change—Gemini has the edge.
Pricing Structures
Of course, power must be weighed against cost. Gemini’s I/O Preview retains Google’s familiar token pricing: $2.50 per million input tokens (dropping to $1.25 under 200K tokens) and $15 per million output tokens (with a $10/M tier for shorter responses). A free tier eases experimentation. Claude stands firm at $3 per million inputs and $15 per million outputs, billing thinking tokens the same as user tokens. In scenarios where you’re feeding in massive prompts without heavy generated output—such as batch code analysis—Gemini’s discounted input rate can translate to meaningful savings.
Performance Benchmarks
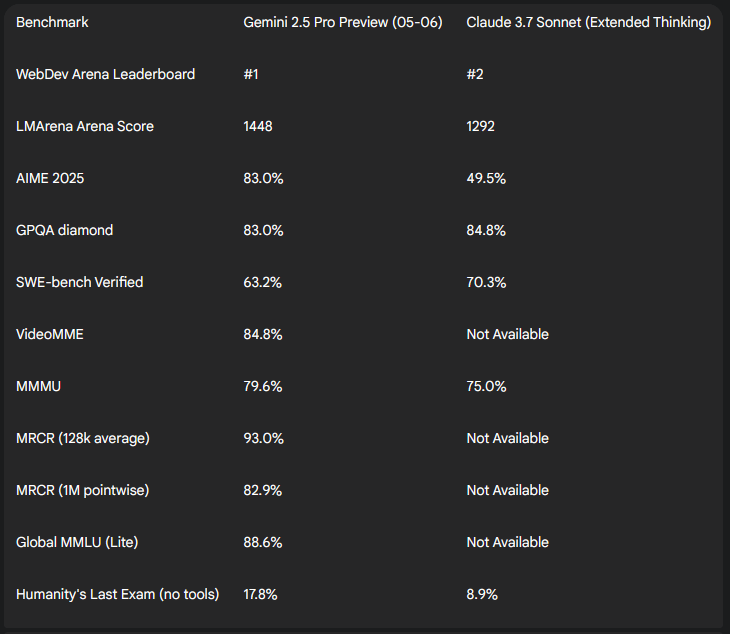
No discussion of these two juggernauts is complete without a look at leaderboard glory. On the WebDev Arena, where human evaluators pit AI-generated web applications head-to-head, Gemini exploded ahead, netting a +147 Elo-point surge over its own predecessor—enough to knock Claude into second place. That margin isn’t just statistical noise; it reflects a consistent preference for Gemini’s UI scaffolding, CSS finesse, and end-to-end deployment scripts.
Broader conversational prowess comes into focus on LMArena’s Chatbot Arena, where blind comparisons yield an “Arena Score.” Here again, Gemini rings up a 1448, comfortably above Claude’s 1292, cementing its reputation as the go-to for developers craving rapid, polished dialogue in chat-based tools.
But coding and conversation are only part of the story. Both models flex on academic benchmarks:
- Mathematics (AIME 2025): Gemini nails 83.0% of pass-@1 problems, leaving Claude’s 49.5% in the dust.
- Scientific Reasoning (GPQA Diamond): Gemini’s 83.0% edges close to Claude’s 84.8% (in extended-thinking mode), showcasing strong STEM chops on both sides.
- Agentic Coding (SWE-bench Verified): Here, Claude strikes back with 70.3% to Gemini’s 63.2%, highlighting Anthropic’s strength in step-by-step algorithmic tasks.
- Video Understanding (VideoMME): At 84.8%, Gemini stands unchallenged—Claude doesn’t even enter this arena.
- Multimodal Reasoning (MMMU): Gemini’s 79.6% surpasses Claude’s 75.0%, another testament to broad media handling.
- Long Context Retention (MRCR 128 K / 1 M): Gemini scores 93.0% / 82.9%, demonstrating robust memory far beyond Claude’s limits.
- Multilingual Proficiency (Global MMLU Lite): 88.6% for Gemini; Claude’s figure isn’t publicly benchmarked here.
- General Knowledge (Humanity’s Last Exam, no tools): 17.8% versus Claude’s 8.9%, a striking gap in world-fact recall.
| Benchmark | Gemini 2.5 Pro Preview (05-06) | Claude 3.7 Sonnet (Extended) |
|---|---|---|
| WebDev Arena Elo | #1 (+147 over prior) | #2 |
| LMArena Arena Score | 1448 | 1292 |
| AIME 2025 | 83.0% | 49.5% |
| GPQA Diamond | 83.0% | 84.8% |
| SWE-bench Verified | 63.2% | 70.3% |
| VideoMME | 84.8% | – |
| MMMU | 79.6% | 75.0% |
| MRCR (128 K / 1 M) | 93.0% / 82.9% | – |
| Global MMLU (Lite) | 88.6% | – |
| Humanity’s Last Exam (no tools) | 17.8% | 8.9% |
Independent Reviews & Developer Feedback
Early adopters have been quick to sing Gemini 2.5 Pro’s praises. Developers rave about its blistering speed—tasks that once dragged on now flash by as Gemini churns through large-scale refactoring like a master sculptor reshaping marble. Stories abound of the model cracking the Cleo Integral, a problem that stumped even seasoned coders, and then immediately scaffolding full-fledged UI projects with minimal prompting. In hackathons and Slack threads alike, users marvel at Gemini’s uncanny ability to autogenerate web‐app prototypes: HTML, CSS, JavaScript—and even serverless hooks—appear in a single shot, ready for refinement.
Yet the honeymoon isn’t without hiccups. Some engineers grumble that those impressive feats come at the cost of longer runtimes—minute‐long waits peppered with status spinners. Others note a certain verbosity: code comments that read like turgid essays, and function signatures festooned with layers of overengineered abstraction. A few lament that, compared to its predecessor, Gemini occasionally drifts from strict prompt instructions—tweaks that feel nicer for conversational tasks but clumsy when you just want a bare‐bones utility function. Prompt adherence regressions, they warn, can cascade into hours spent trimming away politely worded but unnecessary scaffolding.
Claude 3.7 Sonnet, for its part, has earned a reputation as the patient mentor. Its code outputs are lean and precise, each line purposeful; reviewers highlight Claude’s step‐by‐step explanations as a godsend when debugging gnarly edge cases. It doesn’t rush—you’ll wait a beat longer for that clean, well‐commented function, but you’ll get exactly what you asked for, and probably a brief rationale for each design choice. For newcomers or teams using AI as a teaching tool, this “walk‐through” style has proven invaluable, forging trust and understanding where black‐box models often falter.
Still, Claude’s virtues come with trade‐offs. Its 200,000‐token context window forces developers to juggle snippets instead of entire repositories, and complex codebases can quickly bump into that ceiling. Generation speed lags behind Gemini’s breakneck pace, which can frustrate time‐pressed sprints. And at $3 per million tokens in, with no free tier beyond a basic trial, several teams cite sticker‐shock when bills arrive; budget‐minded shops sometimes switch off Claude mid‐project to rein in costs.
Deep-Dive Use Cases
Web Application Development
When spinning up interactive dashboards or landing pages, Gemini consistently steals the show. Its massive context length lets it ingest entire React codebases and churn out feature branches with flawless CSS tweaks and component refactors. Designers report feeding it high-fidelity mockups—screenshots pasted right into the prompt—and watching as Gemini translates visuals into pixel-perfect layouts. For rapid prototyping, nothing else comes close.
Complex Algorithm Implementation
Here, Claude’s deliberate reasoning shines. Toss it a description of a graph‐coloring problem or ask for an optimized Dijkstra implementation, and you’ll get meticulously annotated pseudocode first, then clean, compiles‐on‐the‐first‐run code. Its extended thinking mode logs each inference step, making it easy to spot and correct logical missteps. Teams tackling scientific simulations or bespoke data structures often fall back to Claude when precision and traceability matter.
Multimodal Projects
Gemini truly stretches its legs in the multimedia arena. Developers crafting video‐based tutorials feed in raw clips—fragments of UI walkthroughs, camera footage, or screen recordings—and receive cohesive scripts, chapter markers, and even automated summary transcripts. Audio-driven tasks, like generating code from spoken requirements, flow naturally. Claude, limited to text and images, simply can’t compete in these rich, cross-modal workflows.
Educational & Onboarding Scenarios
In classrooms and code‐review sessions, Claude’s mentor-like persona wins hearts. Instructors use its extended thinking trail as teaching material: students follow the model’s reasoning, learn how it spots edge cases, and observe best practices in real time. New hires appreciate Claude’s knack for breaking down monolithic legacy code into comprehensible chunks. Gemini can handle the content size, but its terser explanations sometimes skip the pedagogical flourishes that make Claude so effective for learning.
Cost-Benefit Analysis
Token Pricing Breakdown
Gemini’s Preview retains Google’s flexible, tiered structure: input tokens run $2.50 per million (dropping to $1.25 under 200K), while outputs cost $15 per million—with a $10/M discount for shorter replies—and a generous free tier for initial experiments. Claude, by contrast, charges a flat $3 per million input tokens and $15 per million outputs, with no sustained free allowance beyond a limited trial. In workflows dominated by hefty prompts—batch code review, long-document summarization or multimodal ingestion—Gemini’s cut-rate input band can slice tooling budgets by as much as 50%.
Total Cost of Ownership
Yet price per token only tells half the story. Several teams have surfaced surprise bills: one AI consultancy reported a single afternoon of Gemini prototyping adding up to a $500 invoice. Even with discounted input rates, runaway loops (e.g., repeatedly regenerated UI scaffolds) can balloon costs if usage isn’t gated. Claude customers, while paying slightly more per input token, cite steadier, more predictable billing—beneficial for enterprises with firm budget caps.
Scalability & Budget Planning
For startups or research labs experimenting at scale, Gemini’s free tier and volume discounts encourage broad adoption—and ‘sandbox sprawl’ that can be tamed only with vigilant monitoring. Claude’s simpler fee structure, though stiffer per token, eases financial forecasting. Teams planning monthly token consumption into the hundreds of millions should weigh Gemini’s aggressive scale discounts against Claude’s billing transparency, then codify clear usage thresholds to avoid fiscal whiplash.
Strategic Positioning & Future Outlook
Ecosystem Roles
Google positions Gemini as the Swiss-Army knife of AI: raw performance, multimodal breadth, seamless Cloud integration. Anthropic casts Claude as the thoughtful tutor: rigorous reasoning, transparent “Thinking Mode,” and a focus on safety guardrails. Both vendors see coding as the killer app—with Google betting on end-to-end developer workflows and Anthropic doubling down on trust and explainability in regulated industries.
Roadmaps on the Horizon
Inside sources suggest Gemini’s context window may swell further—rumors speak of a 2-million-token option by year-end—alongside deeper Vertex AI hooks for real-time data and tool use. Meanwhile, OpenAI’s upcoming ChatGPT reasoning upgrade promises to blur the lines between Claude’s step-by-step mode and more mainstream chat interfaces. Expect Google to respond by enhancing Gemini’s ‘thinking built-in’ explanations, and Anthropic to tease a multimodal Claude sonnet capable of light audio or rudimentary video understanding.
Emerging Competitive Forces
Beyond the Gemini-Claude duel, a new generation of challengers—Musk’s Grok 3, DeepSeek-R1, Qwen, and extensions of open-source LLMs—are staking claims at the nexus of cost, performance, and openness. As giants rush to roll out “reasoning everywhere,” price wars and feature parity fights will reshape these early leadership positions. For now, Gemini and Claude hold distinct peaks—but the ascent of nimble newcomers could redraw the summit map in months.
Conclusions & Recommendations
Task-Driven Model Selection
High-Velocity Web Development: Gemini’s massive context window and UI auto-generation make it the clear first choice.
Deep Algorithmic Logic & Debugging: Claude’s mentor-style, stepwise reasoning gives it the edge for critical, precise implementations.
Multimodal Pipelines (Video/Audio): Gemini alone can handle end-to-end media ingestion and annotation.
Onboarding & Educational Use: Claude’s transparent thinking trails are unmatched for pedagogy and code reviews.
Best Practices & Tool Synergies
Coupling Gemini with context7 MCP (or similar documentation-indexing tools) tames hallucinations and keeps expensive prompts crisp. For teams leaning on Claude, integrating automatic prompt-chunking libraries smooths context-window limits. And in hybrid workflows—prototype in Gemini, refine in Claude—developers can exploit each model’s strengths while containing costs.
Final Verdict
There is no universal champion. For projects that prize raw throughput, long-form context, and rich media capabilities, Gemini 2.5 Pro Preview (05-06) raises the bar. For workflows demanding iron-clad precision, granular explanations, and billing predictability, Claude 3.7 Sonnet remains the steadfast companion. Savvy teams will map their use cases to these sweet spots—then stay nimble, because in 2025’s AI arms race, today’s victor can become tomorrow’s underdog overnight.
Appendice
Appendix A: Detailed Benchmark Comparison
(See table above in “Performance Benchmarks” for side-by-side scores)
Appendix B: Pricing Structures at a Glance
Gemini 2.5 Pro Preview:
• Input: $2.50/M ($1.25/M ≤200K) | Output: $15.00/M ($10.00/M ≤200K) | Free tier available
Claude 3.7 Sonnet:
• Input: $3.00/M | Output: $15.00/M | Trial limited free usage